在当前工业智能化的大潮中,一个引人注目的现象是,尽管95%的制造商声称已布局智能制造,但实际能有效利用数据的企业仅占44%。这一鲜明对比不禁让人质疑,工业大模型的光鲜外表下,是否隐藏着太多的纸上谈兵?我们似乎正置身于一场由资本狂热与技术乌托邦幻想共同编织的“智能盛宴”,而工厂生产线上的机器,却依然在等待真正的智能觉醒。
这并非夸大其词,而是工业智能化进程中的真实写照。从概念的萌芽到资本的蜂拥,工业大模型被推到了前所未有的高度。然而,当我们从华丽的发布会和融资捷报中抽身,将目光转向工厂车间的实际场景,便会发现理想与现实之间存在着一条难以逾越的技术鸿沟。面对这场关乎未来的变革,我们迫切需要冷静下来,仔细分辨哪些是终将熄灭的“虚火”,哪些又是能够点燃第四次工业革命的“真金”。
在工业大模型的喧嚣背后,存在着由资本、技术和应用场景构成的三重泡沫,它们相互交织,营造出一种虚假的繁荣。
首先,资本泡沫尤为显著。在资本市场上,我们看到的是一场巨大的赌博:融资规模与商业回报严重失衡。以OpenAI为例,其技术突破令人瞩目,但每年数十亿美元的亏损也令人咋舌。这种“烧钱换未来”的模式在工业领域被广泛复制,资本更关注模型的参数规模、计算能力等技术指标,而非其在具体工业场景中的实际应用价值。技术供应商往往过度包装尚处于实验室阶段的技术,将其吹嘘为“万能钥匙”,承诺解决从研发到生产的所有问题,导致估值与实效严重脱节,大量投资被浪费在无法落地的概念验证上。
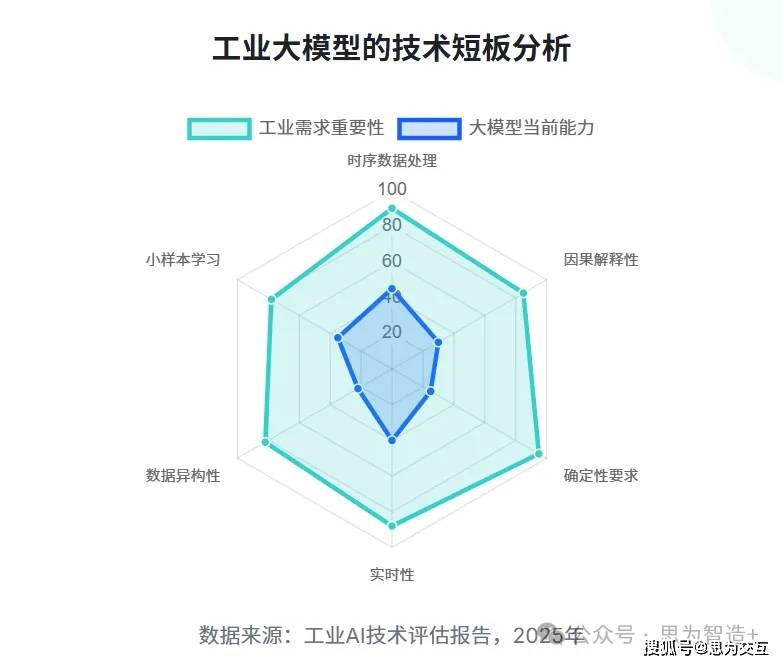
其次,技术泡沫同样不容忽视。工业大模型的通用技术基因与严苛的工业需求之间存在根本性错配。工业场景要求极高的确定性,无论是产线的控制指令、故障预警还是工艺优化方案,都需要极高的准确性和实时性。然而,当前的大模型在处理开放性、模糊性的自然语言任务方面表现出色,却难以胜任工业场景中的高频、连续时序数据处理,更无法进行反事实推断。工业数据的质量、标注和异构性问题也为模型的训练和应用带来了巨大挑战。
再者,应用场景的泡沫也不容小觑。在工业大模型的发布会上,我们常听到“赋能科学发现”、“自动生成设计图纸”等颠覆性的愿景。然而,现实中真正能够落地的应用场景仍然有限,主要集中在质检、预测性维护、能耗优化等基础领域。公众和市场的过高期望掩盖了工业大模型走向成熟所必须经历的艰难历程,当PPT上的美好愿景无法在车间兑现时,泡沫的破裂便在所难免。
然而,这并不意味着我们应该否定工业大模型的潜力。相反,只有正视问题,才能找到点燃“真火”的正确路径。这需要我们从根本上重塑工业大模型的发展范式。
一方面,我们需要将工业属性融入技术基因。真正的工业大模型不能是通用模型的简单改造,而必须从底层注入工业知识。通过将物理规则、化学方程式、材料力学原理等工业知识内嵌到模型中,可以大幅提升其在实际应用中的准确性和可靠性。采用分层架构也是未来的发展趋势,通过基座模型、任务模型和领域模型的协同工作,让技术真正扎根于具体的业务流程中。
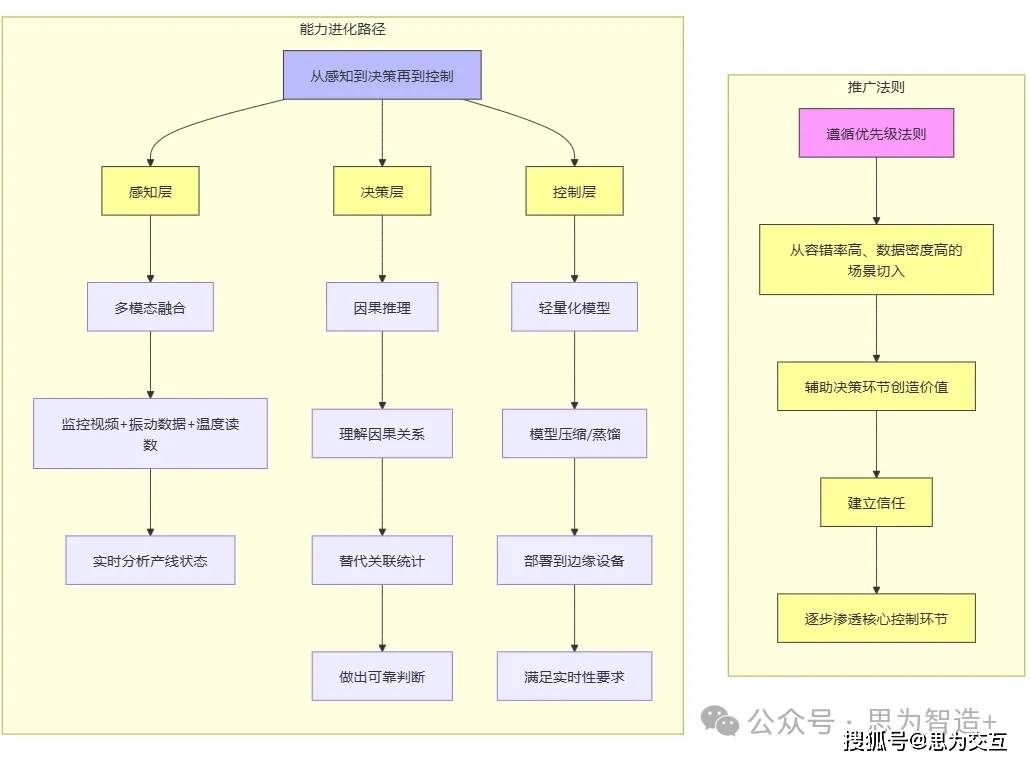
另一方面,我们需要从高价值场景进行收敛式创新。与其盲目追求“万能”的解决方案,不如脚踏实地,从容错率高、数据密度高的场景切入。通过先在辅助决策环节创造价值、建立信任,再逐步向核心控制环节渗透的方式,实现工业AI的稳步推广。同时,明确工业AI的能力进化路径,从感知层到决策层再到控制层,逐步实现技术的深度应用。
最后,我们还需要构建坚实的工业化底座。这包括构建行业知识图谱与企业暗数据解析的二元语料库、优化推理成本以降低模型在实际应用中的运行成本、以及发展可解释性算法以提升模型的可信度。只有当数据、算力和可信度得到全面提升时,工业大模型才能真正成为推动生产力革命的强大动力。
从“PPT智能”到“生产力革命”,需要的不是更多的概念包装与资本故事,而是一场深刻的范式转变。这场转变的核心在于让技术回归谦卑、尊重工业的客观规律、将智能的根系深植于生产的土壤之中。只有当代码的逻辑与螺栓的物理特性紧密结合、算法的优化能够带来实实在在的良率提升和成本下降时,工业大模型的“真火”才能真正照亮未来的道路。