
字节跳动近期发布了一份英文版技术报告,详细介绍了其最新的Seed1.5-Thinking混合专家模型(MoE)。该模型拥有200亿激活参数和高达2000亿的总参数,展现了卓越的推理能力。
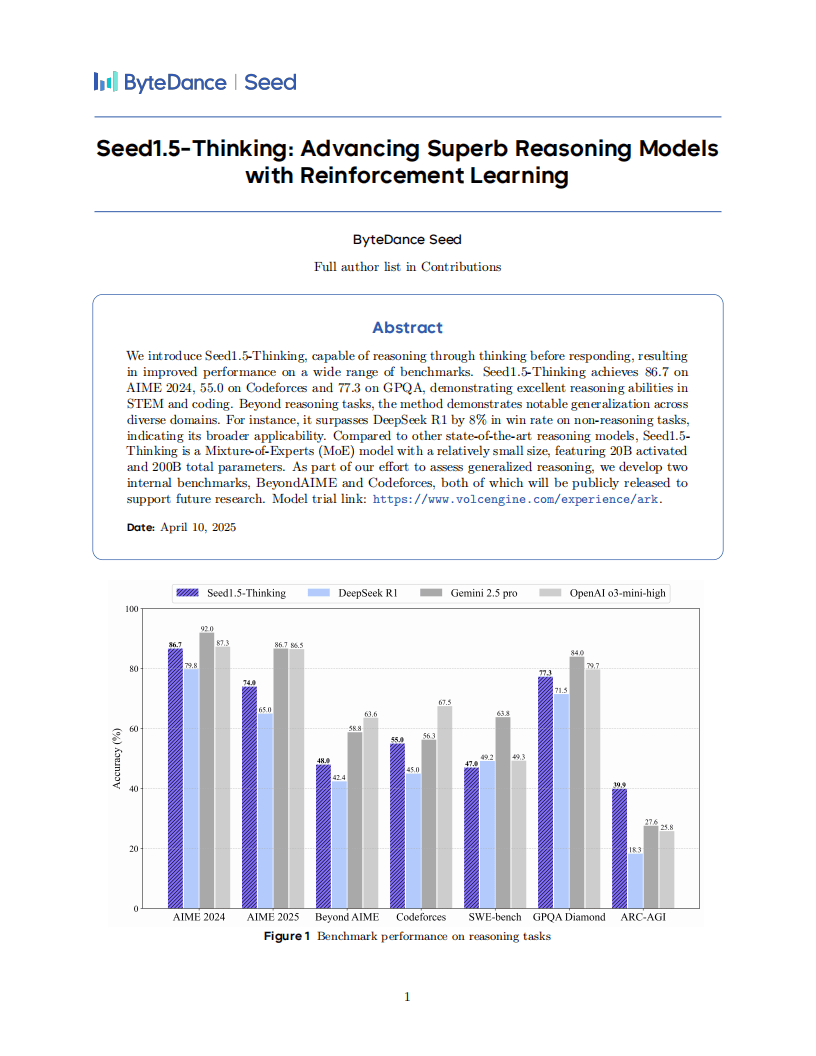
在多个基准测试中,Seed1.5-Thinking的表现尤为亮眼。在AIME 2024竞赛中,它获得了86.7分的高分;在Codeforces平台上也取得了55.0分的佳绩;而在GPQA测试中,则获得了77.3分。这些成绩不仅证明了该模型在STEM和编程领域的强大实力,还显示出在非推理任务上的广泛适用性。与DeepSeek R1相比,Seed1.5-Thinking的胜率更是高出了8%。
在模型开发方面,字节跳动团队强调了数据、强化学习(RL)算法和RL基础设施的重要性。数据方面,他们采用监督微调(SFT)方法,并依赖于链式思维(CoT)数据。然而,过多的非CoT数据可能会降低模型的探索能力。RL训练数据则涵盖了STEM问题、代码任务等多个领域,其中数学数据的泛化能力尤为突出,能够全面提升各任务的性能。
针对RL算法训练中的不稳定性问题,字节跳动团队自主研发了VAPO和DAPO框架。这两个框架分别针对演员-评论家及策略梯度范式,有效解决了训练不稳定的问题,确保了模型的稳健性。
在RL基础设施方面,团队采用了混合引擎架构,并引入了Streaming Rollout System(SRS)。这一系统能够缓解长响应生成中的滞后问题,结合多种并行机制和内存优化策略,进一步提升了训练效率和可扩展性。
评估结果显示,Seed1.5-Thinking在数学推理方面与OpenAI的o3-mini-high表现相当,但在AIME 2025和BeyondAIME等更高级别的测试中仍存在一定差距。在科学领域的GPQA测试中,该模型接近o3水平;在编程方面,则接近Gemini 2.5 Pro的性能。在逻辑推理的ARC-AGI测试中,Seed1.5-Thinking更是展现出了突出的表现。人类评估显示,该模型在非推理场景的整体胜率超过DeepSeek R1达8.0%,且更符合人类的偏好。

字节跳动团队表示,他们将继续探索更高效的强化学习方法,挑战更复杂的任务,并研究通用奖励建模,以进一步提升模型的智能边界。同时,他们计划公开BeyondAIME和Codeforces等内部基准,为相关领域的研究提供有力支持。











