
阿里通义近日在人工智能领域再掀波澜,其全新发布的基础模型架构Qwen3-Next凭借突破性技术引发行业关注。这款以"高效计算"为核心设计的模型,通过创新架构将800亿参数模型中的30亿参数激活,即可达到与旗舰版2350亿参数模型相当的性能表现,标志着大模型训练与推理效率迈入全新阶段。
技术团队在架构设计上实现了多项革新。相较于前代Qwen3的混合专家(MoE)模型,新一代架构引入混合注意力机制、超高稀疏度MoE结构及多token预测(MTP)技术。其中最引人注目的是1:50的专家激活比例,较前代1:16的稀疏度提升超3倍,在保持计算效率的同时显著降低资源消耗。测试数据显示,新模型训练成本较320亿参数密集模型降低90%以上,长文本处理吞吐量提升达10倍。
在性能评测环节,Qwen3-Next系列展现出惊人实力。指令模型(Instruct)在编程能力(LiveCodeBench v6)、人类偏好对齐(Arena-Hard v2)等核心指标上超越自家2350亿参数旗舰模型,通用知识(SuperGPQA)和数学推理(AIME25)测试中全面领先320亿参数密集模型。推理模型(Thinking)更是在数学推理测试中取得87.8分的优异成绩,超越Gemini2.5-Flash-Thinking等国际主流模型。
针对超长上下文处理这一行业痛点,研发团队重构了Transformer核心组件。通过结合Gated DeltaNet线性注意力与自研门控注意力机制,新模型在保持精度的同时大幅降低内存占用。预训练阶段采用的多token预测技术,使模型在处理超32K tokens的长文本时,推理效率较前代提升一个数量级。这种技术突破为未来大模型处理复杂任务提供了可行路径。
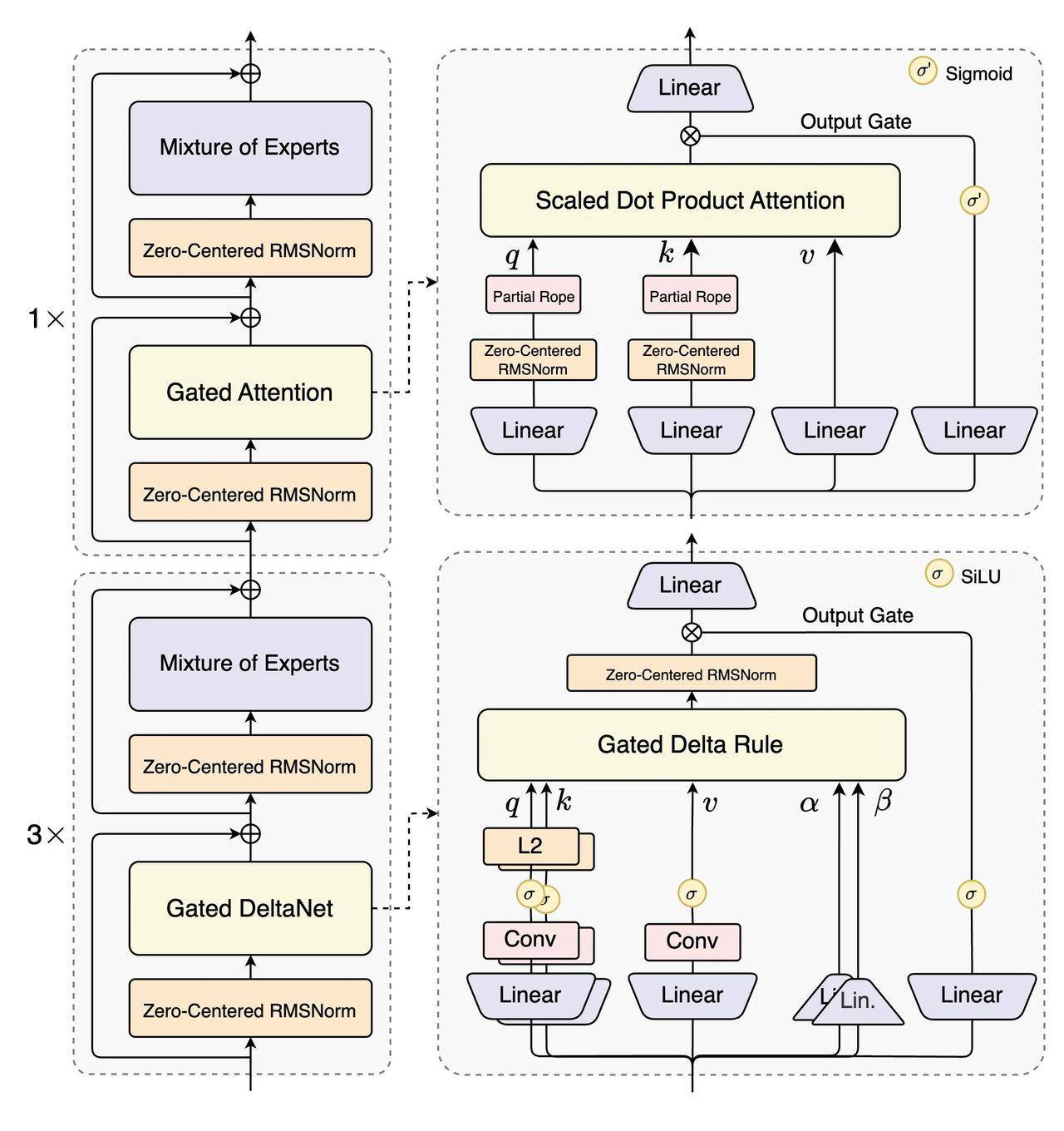
开源生态建设方面,通义团队同步开放了Qwen3-Next-80B-A3B指令模型和推理模型。基于15万亿token的精简预训练数据集,新模型仅用前代9.3%的计算资源就完成训练,在强化学习阶段更解决了稳定性与效率的长期矛盾。这种"小算力大作为"的实现方式,为资源有限的研究机构提供了新的发展范式。
在产品矩阵拓展上,阿里通义近期动作不断。继推出超万亿参数的Qwen3-Max-Preview后,文生图编辑模型Qwen-Image-edit和语音识别模型Qwen3-ASR-Flash相继问世。全球最大开源社区HuggingFace数据显示,基于通义千问开发的衍生模型已超过17万个,稳居全球开源模型榜首。沙利文报告证实,2025年上半年中国企业级大模型市场中,通义千问以17.7%的调用量占比领跑行业。










