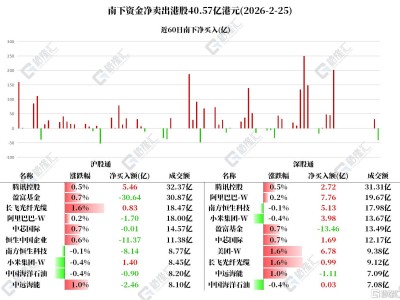
谷歌研究院近日在机器学习领域取得重要突破,针对大语言模型持续学习时面临的“灾难性遗忘”难题,提出名为“嵌套学习”的全新范式,相关成果已发表于国际顶级会议NeurIPS 2025。
传统大语言模型虽具备强大能力,但知识获取方式存在显著局限。其知识体系主要依赖预训练阶段的静态数据,或受限于有限的上下文窗口长度,无法像人类大脑般通过“神经可塑性”机制动态更新知识——即根据新经验调整认知结构而不丢失原有能力。当直接用新数据覆盖旧模型时,常出现新任务表现提升但旧任务性能断崖式下降的“灾难性遗忘”现象。
研究团队提出的嵌套学习范式,通过重构机器学习模型的底层架构解决了这一矛盾。该范式将复杂模型视为多层次嵌套的优化问题集合,每个子问题拥有独立的“上下文流”和更新节奏。这种设计突破了传统模型架构与优化算法分离的局限,为构建计算深度更强的AI组件提供了新维度。
基于该理论框架,研究团队开发了两项关键技术:一是“深度优化器”,通过将优化过程本身转化为可学习模块,并优化其目标函数设计,使模型对数据噪声和分布变化具有更强适应性;二是“连续体内存系统”,该系统将模型记忆分解为多个更新频率不同的模块,形成从短期到长期的平滑过渡,构建出更高效的持续学习内存架构。
为验证理论有效性,团队构建了名为“Hope”的概念验证模型。该模型基于Titans架构设计,通过自修改循环网络深度整合连续体内存系统,实现多层级上下文学习。实验数据显示,在语言建模和常识推理任务中,Hope模型的困惑度指标较现代循环模型和标准Transformer显著降低,准确率大幅提升。
在针对长文本处理能力的“大海捞针”测试中,Hope模型展现出卓越优势。该测试要求模型从超长文本中精准定位并回答特定问题,实验结果表明,连续体内存系统能有效处理超长信息序列,为开发具备持续学习能力的AI系统提供了关键技术路径。
据悉,“大海捞针”测试是评估大语言模型长文本理解能力的重要基准,通过模拟从海量信息中提取关键内容场景,验证模型在真实应用场景中的信息检索可靠性。此次突破标志着AI模型向“温故知新”的类人学习能力迈出重要一步。