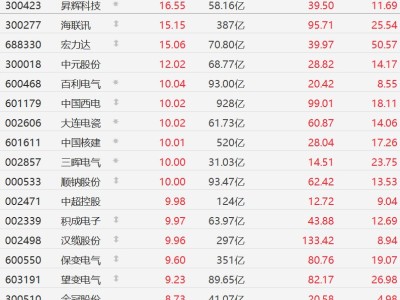
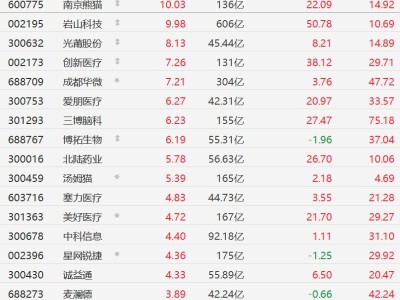
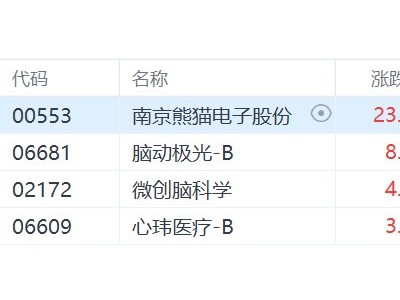
在人工智能大模型竞争愈发激烈的当下,DeepSeek于近日推出两款全新模型——DeepSeek-V3.2与DeepSeek-V3.2-Speciale,引发行业高度关注。这两款模型同步发布的技术论文显示,其推理能力已达到全球领先水平,为当前大模型领域注入新的活力。
DeepSeek-V3.2作为常规版本,在网页端、移动应用及API接口均已完成更新。该模型着重平衡推理能力与输出长度,旨在满足日常使用需求。在基准测试中,V3.2与GPT-5、Claude 4.5等头部模型在不同领域互有胜负,仅Gemini 3 Pro在综合表现上略占优势。相较于国产大模型厂商月之暗面近期发布的Kimi-K2-Thinking,V3.2在输出长度上显著缩短,有效降低了计算资源消耗与用户等待时间。在智能体评测中,V3.2得分超越Kimi-K2-Thinking及MiniMax M2,成为当前开源模型中的佼佼者,其性能已接近闭源模型的巅峰水平。
V3.2在实际应用场景中的表现尤为突出。在旅游攻略咨询等具体任务中,该模型通过深度思考与工具调用(如网站爬虫、搜索引擎等),生成了详尽且精准的解决方案。其更新的API首次支持在思考模式下调用工具,大幅提升了答案的丰富度与适用性。值得注意的是,DeepSeek强调,V3.2未针对测试集工具进行特殊训练,这一特点使其在真实场景中展现出更强的泛化能力。
针对当前大模型普遍存在的“高智商低情商”问题——即在测试中得分优异却难以处理用户简单需求,DeepSeek通过技术优化寻求突破。V3.2在训练、整合及应用层面进行全方位改进,引入DSA(DeepSeek稀疏注意力机制),在长文本场景中降低计算复杂度,同时保持模型性能。团队开发了新的合成流程,系统性生成大规模训练数据,显著提升了模型在复杂交互环境中的泛化与指令跟随能力。这些优化使V3.2成为首个将思考融入工具使用的模型,进一步增强了其适应多样化任务的能力。
与V3.2的平衡性定位不同,V3.2-Speciale作为“长思考特种部队”,致力于将开源模型的推理能力推向极致。该模型整合了上周发布的数学大模型DeepSeek-Math-V2的定理证明能力。Math-V2此前在国际数学奥林匹克竞赛及中国数学奥林匹克竞赛中均获金牌级成绩,并在IMO-Proof Bench基准测试中超越Gemini 3。通过自验证机制,Math-V2突破了传统AI在深度推理中的局限,形成了更稳定、实用的定理证明能力。V3.2-Speciale继承这一优势,在主流推理基准测试中取得与Gemini 3.0 Pro相当的成绩。然而,由于其高推理强度需消耗大量计算资源,目前该模型仅支持研究用途,暂不支持工具调用及日常对话、写作功能。