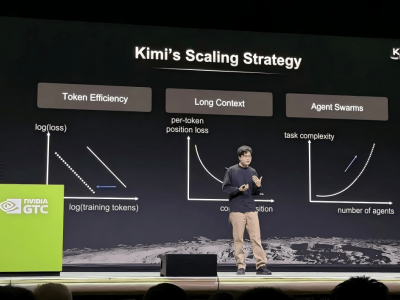
在国产GPU技术发展进程中,摩尔线程近日成为行业焦点。这家被市场视为“中国版英伟达”的芯片厂商,在MUSA开发者大会上首次对外公布其GPU技术路线图,集中发布新一代全功能GPU架构“花港”,并同步推出多款芯片产品及万卡智算集群等新成果。
GPU架构作为芯片设计的核心蓝图,直接影响计算核心的排列方式、数据流动路径以及整体计算效率。据介绍,“花港”架构在计算性能上实现显著突破。基于新一代指令集,其算力密度提升50%,效能提升达10倍。该架构支持从FP4到FP64的全精度计算,浮点数精度越高,计算结果越精细,但同时也对算力消耗提出更高要求。
摩尔线程创始人、董事长兼CEO张建中在现场指出,当前国产GPU工艺发展速度相对滞后,尚未达到国际先进水平。在此背景下,提升算力效率成为关键突破口。通过设计全新指令集,摩尔线程在相同芯片面积下实现了算力密度的充分提升。同时,针对功耗和散热这一制约算力扩展的核心瓶颈,团队对芯片架构进行深度优化,确保在相同功耗条件下提供更强的算力支持。
基于“花港”架构,摩尔线程公布了两款未来芯片的技术路线:定位AI训推一体与超大规模智能计算的“华山”芯片,以及专注高性能图形渲染的“庐山”芯片。其中,“华山”芯片在浮点算力、高速互联带宽等核心指标上,整体水平介于英伟达上一代Hopper架构与新一代Blackwell架构之间,访存带宽接近Blackwell水平,访存容量则优于这两代产品;“庐山”芯片则可为3A游戏、高端图形创作等领域提供算力支撑。
回顾产品迭代历程,摩尔线程保持一年一更新的节奏。2024年推出的“曲院”架构,催生了首款训推一体AI计算卡S4000及首个千卡集群;2025年采用“平湖”架构的S5000芯片实现量产,万卡集群已支持万亿参数级大模型训练。张建中透露,未来集群规模将进一步扩展至50万卡、100万卡,以应对算力扩展的挑战。
摩尔线程的创始团队与英伟达渊源深厚。张建中曾任职英伟达全球副总裁、中国区总经理长达14年,联创周苑曾任英伟达市场生态高级总监,另一联创张钰勃则担任过GPU架构师,是核心技术成员之一。这种技术基因的传承,为摩尔线程的发展奠定了基础。
资本市场方面,摩尔线程于12月初登陆上交所科创板,发行价114.28元/股,发行市值约537亿元。截至12月19日,股价累计涨幅达481%,收报664.10元/股,市值跃升至约3121亿元。此次IPO发行7000万股,募集资金总额近80亿元,实际净额75.76亿元。资金将用于新一代AI训推一体芯片、图形芯片、AI SoC芯片研发项目及补充流动资金。12月13日,公司公告称计划使用最高75亿元闲置募集资金进行现金管理,以提升资金使用效率。
财务数据显示,2022-2024年摩尔线程扣非净亏损分别为14.1亿元、16.9亿元、15.1亿元,今年上半年亏损3.17亿元。公司解释称,尽管收入增长较快,但绝对金额仍较小,同时为保持技术先进性,三年研发投入累计达38.1亿元,导致研发费用金额较高。
国产芯片领域正迎来上市热潮。12月17日,另一家GPU企业沐曦登陆科创板,发行价104.66元/股,截至12月19日股价涨至715.60元/股,较发行价上涨约584%。壁仞科技、天数智芯本周先后通过港交所聆讯,竞逐“港股GPU第一股”称号。