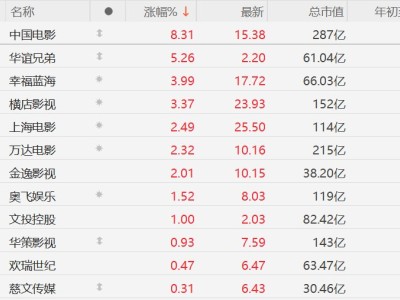
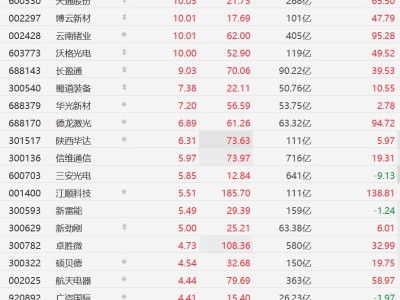
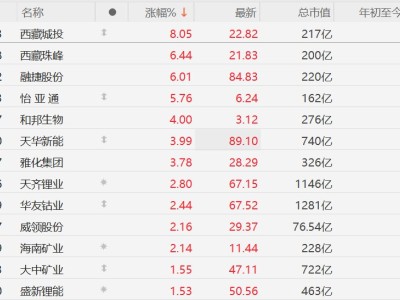
近日,一桩涉及科技巨头苹果公司的法律纠纷引发广泛关注。据外媒披露,两名作家向美国北加州联邦法院提起集体诉讼,指控苹果公司在训练其人工智能系统时非法使用了受版权保护的书籍内容。
诉讼文件显示,作家格雷迪·亨德里克斯和詹妮弗·罗伯逊声称,苹果公司未经授权复制了他们的作品,并将其用于训练名为“OpenELM”的大型语言模型。原告指出,苹果不仅未获得使用许可,也未提供任何形式的补偿或署名。
案件核心争议在于,苹果被指使用包含盗版内容的数据库训练AI系统。两位原告分别来自纽约和亚利桑那州,他们强调自己的作品被包含在未经授权的数据集中,而苹果公司未就这一可能带来巨额收益的技术应用向创作者支付费用。
截至目前,苹果公司及涉事方律师均未对媒体询问作出回应。这起诉讼被视为人工智能领域知识产权保护争议的最新案例,反映出技术发展与版权保护之间的深层矛盾。
值得注意的是,类似纠纷正呈现扩大化趋势。人工智能初创公司Anthropic本周披露,已与一群作家达成15亿美元的和解协议。这些作家指控该公司未经许可使用其作品训练聊天机器人Claude。尽管Anthropic未承认责任,但该和解被律师称为“史上规模最大的公开报道版权赔偿案”。
更早前,微软因使用作家作品训练Megatron人工智能模型遭集体诉讼,meta Platforms和微软支持的OpenAI也面临滥用版权材料的指控。这些案件共同指向一个核心问题:在AI技术快速迭代的背景下,如何平衡技术创新与创作者权益保护。
法律专家指出,当前全球范围内针对AI训练数据侵权的诉讼数量持续上升,反映出数字时代版权法律体系的适应性挑战。随着更多创作者意识到自身权益可能受损,类似纠纷或将进一步激化。