在WAVE SUMMIT深度学习开发者大会2025的现场,百度宣布开源其最新研发的ERNIE-4.5-21B-A3B-Thinking思考模型,引发行业广泛关注。这款基于混合专家(MoE)架构构建的模型,总参数规模达210亿,通过指令微调与强化学习技术训练,每个token激活30亿参数,在逻辑推理、数学计算、科学分析、代码与文本生成等需要专业知识的领域展现出显著提升。
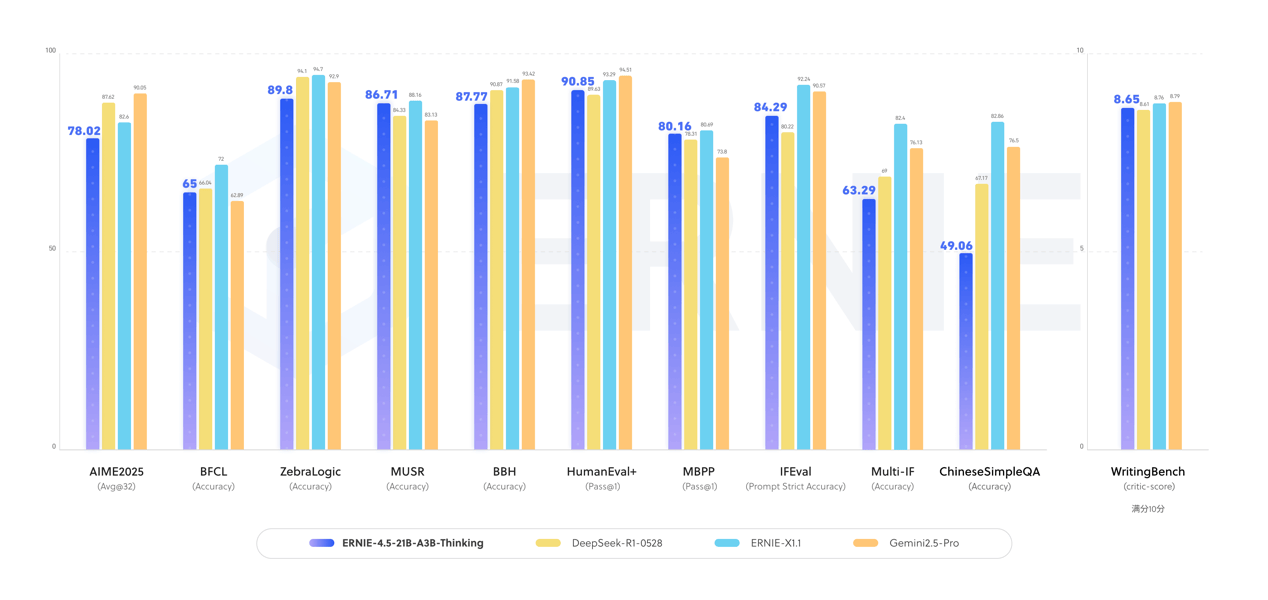
据技术团队介绍,ERNIE-4.5-21B-A3B-Thinking在工具调用能力方面表现突出,可高效支持复杂任务的自动化处理。其128的上下文窗口设计,使其在需要长文本推理的场景中具备独特优势。该模型以Apache License 2.0协议开源,允许商业用途,目前已在HuggingFace、星河社区等主流开源平台同步发布,FastDeploy、vLLM、Transformers等工具链已完成适配,开发者可直接调用。
此次开源的ERNIE-4.5-21B-A3B-Thinking,是在ERNIE-4.5-21B-A3B基础模型上通过深度思考训练优化而来。技术文档显示,该模型在保持210亿参数规模的同时,通过动态参数激活机制实现了计算效率与性能的平衡,特别适用于需要多步骤推理的复杂场景。
同步发布的文心大模型X1.1深度思考模型同样引发关注。该版本在事实准确性、指令遵循能力、智能体交互等方面实现突破性提升。目前,用户可通过文心一言官网、文小言APP体验新模型,企业客户与开发者则可通过百度智能云千帆平台获取完整服务。
回顾今年6月30日,百度曾开源文心大模型4.5系列,包含47B、3B激活参数的MoE模型及0.3B稠密模型等10款变体,实现预训练权重与推理代码的完全公开。此次双模型发布,标志着百度在开源大模型领域的持续深耕,其技术成果已在多个行业场景中实现规模化应用。