
阿里云通义团队近日宣布推出新一代基础模型架构Qwen3-Next,并同步开源基于该架构的Qwen3-Next-80B-A3B系列模型。这一创新架构聚焦长上下文处理与大规模参数效率,通过多项技术突破实现了训练与推理成本的显著优化。

据研发团队介绍,Qwen3-Next架构在Qwen3原有MoE模型基础上进行了四项核心升级:引入混合注意力机制(Hybrid Attention),采用高稀疏度MoE结构,优化训练稳定性,并开发多token预测机制。其中混合注意力模块融合Gated DeltaNet与Gated Attention技术,在保持长文本处理能力的同时降低计算复杂度。
最新开源的Qwen3-Next-80B-A3B-Base模型采用超稀疏MoE架构,总参数达800亿但仅激活30亿参数。该模型通过512个专家模块与动态路由机制(每次激活10个专家+1个共享专家),在32k以上上下文场景下的推理吞吐量较Qwen3-32B提升十倍以上,而训练成本不足其十分之一。测试数据显示,Base模型性能已接近Qwen3-32B密集模型的水平。
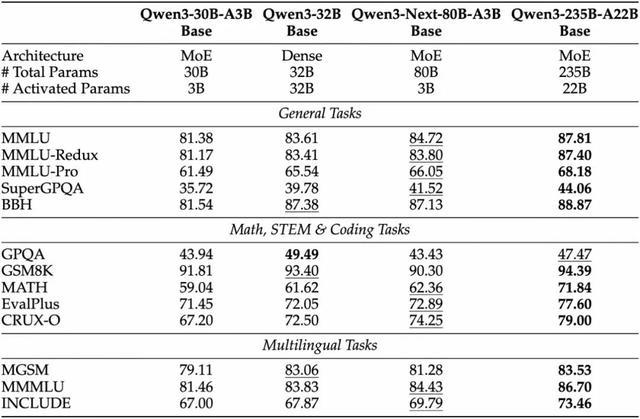
在应用性能方面,该架构衍生的Instruct版本在多个基准测试中接近Qwen3-235B模型表现,Thinking版本则在部分复杂推理任务上超越Gemini-2.5-Flash-Thinking。更值得关注的是,模型原生支持262K tokens上下文窗口,经测试可外推至约101万tokens的长文本处理能力。
技术团队特别强调,Qwen3-Next通过架构创新同时实现了大规模参数容量、低激活计算开销、长上下文支持三大目标。其动态稀疏激活机制与并行推理优化,使模型在保持高性能的同时显著降低资源消耗,这种平衡在同类架构中具有示范意义。
目前,Qwen3-Next-80B-A3B系列模型权重已在Hugging Face平台以Apache-2.0协议开源,支持通过Transformers、SGLang、vLLM等主流框架部署。第三方平台OpenRouter也已完成适配上线,开发者可便捷调用相关能力。











