
在当今复杂的交通环境中,驾驶者往往面临信息获取的局限。当车辆行驶至交叉路口时,视线范围仅限于眼前数十米的车流;而在高速公路上疾驰时,前方数公里外的突发状况却难以提前察觉。这种信息盲区导致驾驶决策缺乏全局性,成为影响出行效率与安全的重要因素。为解决这一难题,高德地图通过技术创新推出TrafficVLM交通视觉语言模型,为驾驶者构建起"数字天眼"系统。
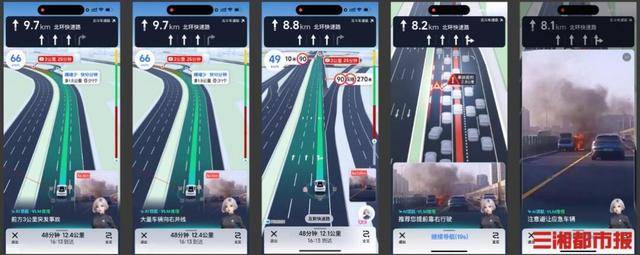
该模型依托空间智能架构实现技术突破,通过云端实时运算系统,以分钟级频率对道路交通态势进行动态解析。当驾驶者使用导航时,系统在后台同步构建数字孪生交通场景,将物理世界的道路信息转化为可计算的数字模型。例如在某次实际测试中,前方3公里处发生追尾事故导致左侧车道堵塞,系统立即识别出事故点并预测拥堵蔓延趋势,在用户到达前5分钟推送避让建议:"前方事故导致左侧拥堵,建议提前变道至右侧车道,注意避让救援车辆"。
与传统导航的单一文字提示不同,TrafficVLM创新性地引入可视化决策支持系统。用户点击导航界面特定区域后,系统自动调取事故现场的实时影像,通过深度学习算法解析车辆运动轨迹、道路空间结构等关键信息。这种三维立体的呈现方式,使驾驶者不仅能直观看到拥堵位置,更能理解拥堵形成原因、影响范围及最佳应对策略。在广州老城区狭窄道路的测试中,系统成功还原了复杂路网中的车辆交互关系,为驾驶者提供精准的变道时机建议。
支撑这项技术的是高德自主研发的交通孪生还原系统,该系统具备"全域覆盖、实时更新"的核心能力。无论是北京国贸桥的立体交通枢纽,还是重庆山城的复杂坡道,系统都能在1秒内构建出与现实世界同步的数字交通模型。通过整合超过2000万个道路节点的实时数据,系统每分钟可生成数万帧动态交通画面,为AI模型提供持续优化的训练素材。
在技术实现层面,TrafficVLM以通义Qwen-VL视觉语言模型为基础架构,通过百万级交通场景数据的强化训练,形成了独特的交通语义理解能力。模型训练过程中,研发团队特别构建了包含3000种典型交通场景的数据集,涵盖异常事件识别、车流动态预测、决策建议生成等核心模块。经过持续优化,系统对交通信号灯状态识别的准确率达到99.2%,对突发事件的响应时间缩短至8秒以内。
该模型构建了完整的智能决策闭环:从道路要素识别、车辆交互分析,到拥堵趋势预测、最优路径规划。在深圳某次早高峰测试中,系统提前12分钟预测到因送学车辆增多导致的学校路段拥堵,通过动态调整导航路线,使测试车辆通行时间减少23%。这种从被动提示到主动决策的转变,标志着导航系统正式进入智能决策时代。
通过将交通孪生技术与视觉语言模型深度融合,高德地图重新定义了智能导航的标准。系统不仅能够感知当前交通状态,更能预测未来15分钟内的演变趋势,将复杂的交通博弈转化为直观的决策建议。这项技术创新不仅提升了导航系统的实用性,更为自动驾驶时代的车路协同奠定了技术基础,展现出AI技术在交通领域的巨大应用潜力。
















