
近期,字节跳动公开了一份英文版技术报告,深入介绍了其最新研发的混合专家模型——Seed1.5-Thinking。这款模型凭借惊人的200亿激活参数和总计2000亿参数的配置,在多个基准测试中展现了卓越的逻辑推理能力。
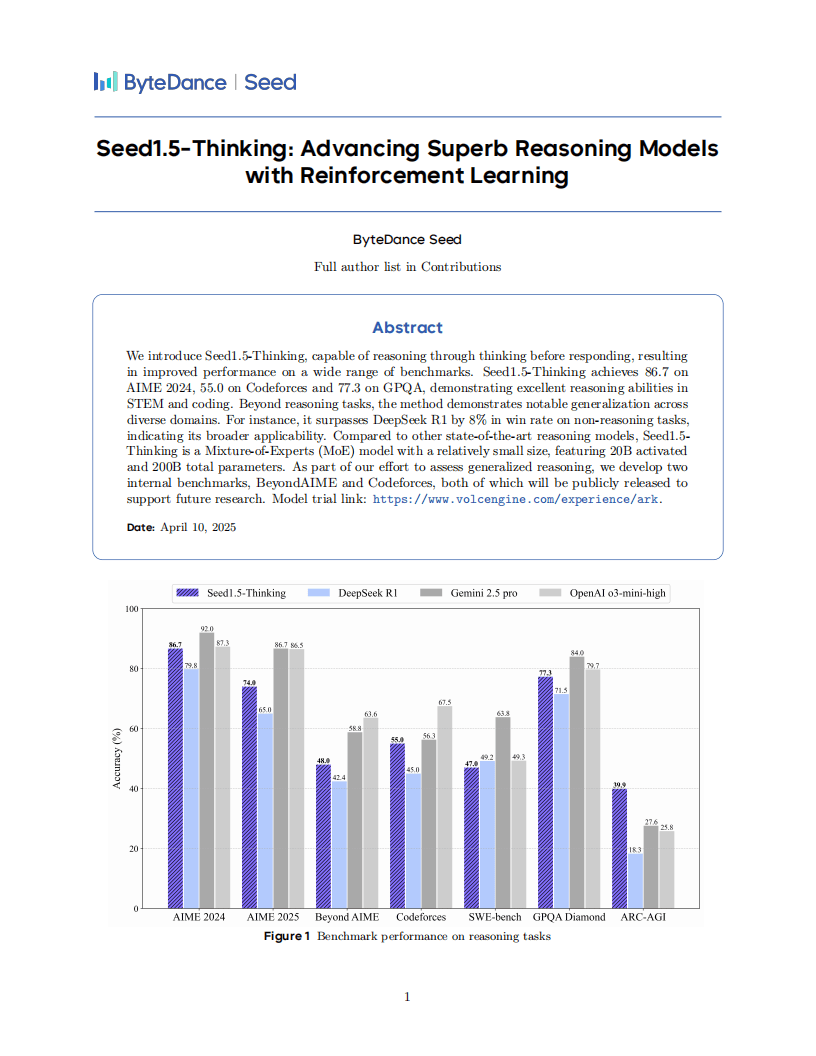
在备受瞩目的AIME 2024、Codeforces以及GPQA等测试中,Seed1.5-Thinking分别斩获了86.7分、55.0分和77.3分的高分,特别是在STEM和编程领域,该模型的表现尤为亮眼。不仅如此,在非推理任务上,Seed1.5-Thinking也展现出了强大的泛化能力,在与DeepSeek R1的对比中,胜率更是高出了8%。
在模型研发过程中,字节跳动团队尤为重视数据、强化学习算法以及强化学习基础设施这三大核心要素。在数据方面,团队采用了监督微调(SFT)技术,主要依赖于链式思维(CoT)数据。然而,他们也发现,过多的非CoT数据可能会对模型的探索能力产生不利影响。因此,在强化学习训练数据的选取上,他们精心挑选了涵盖STEM问题、代码任务等四大类的数据,其中数学数据因其强大的泛化能力,对提升模型在各任务中的表现起到了关键作用。
在强化学习算法层面,字节跳动团队同样取得了显著进展。他们研发了VAPO和DAPO两大框架,分别针对演员-评论家及策略梯度范式,有效解决了模型训练中的不稳定性问题,确保了训练的顺利进行。同时,在强化学习基础设施方面,他们采用了混合引擎架构,并引入了Streaming Rollout System(SRS),有效缓解了长响应生成中的滞后问题。结合多种并行机制和内存优化策略,训练效率和可扩展性得到了显著提升。
评估结果显示,在数学推理领域,Seed1.5-Thinking在AIME 2024中的表现与OpenAI的o3-mini-high难分伯仲。然而,在更高难度的AIME 2025和BeyondAIME等测试中,该模型仍存在一定的提升空间。在科学领域的GPQA测试中,Seed1.5-Thinking的表现接近o3水平;在编程方面,则与Gemini 2.5 Pro旗鼓相当。在逻辑推理的ARC-AGI测试中,Seed1.5-Thinking展现出了令人瞩目的表现。
在人类评估环节,Seed1.5-Thinking在非推理场景的整体胜率超过了DeepSeek R1 8.0%,且其答案更加贴近人类思维方式。这一结果表明,该模型在提升智能水平的同时,也充分考虑了与人类思维方式的契合度。













