近期,科技界传来一则关于苹果公司的创新进展。据悉,苹果的研究团队在最新发表的论文中,提出了一种名为“基于清单反馈的强化学习”(RLCF)的新方法,该方法旨在提升大语言模型(LLMs)执行复杂指令的能力。
与传统的“人类反馈强化学习”(RLHF)方式不同,RLCF不再依赖于简单的人工点赞或点踩评分。相反,它为用户指令生成具体的检查清单,每项内容都按照0-100分的标准进行评分。这种精细化的反馈机制,被认为能够更有效地指导模型的优化过程。
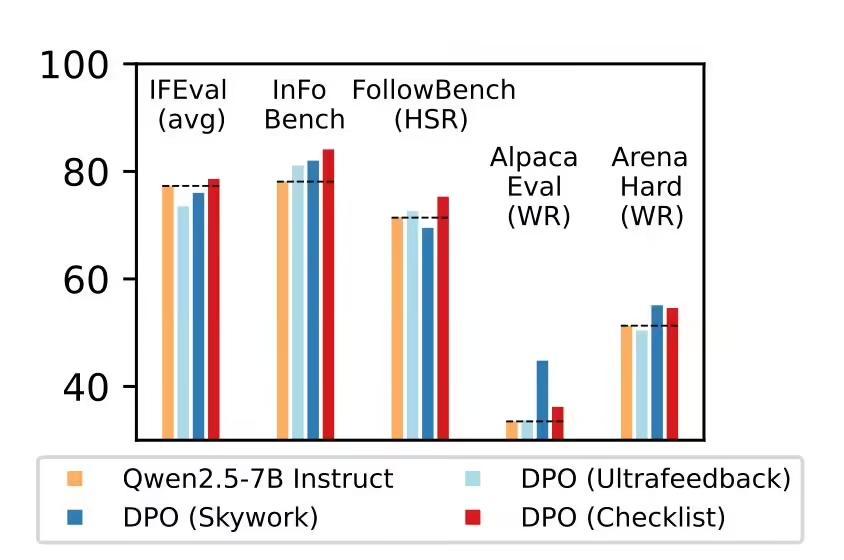
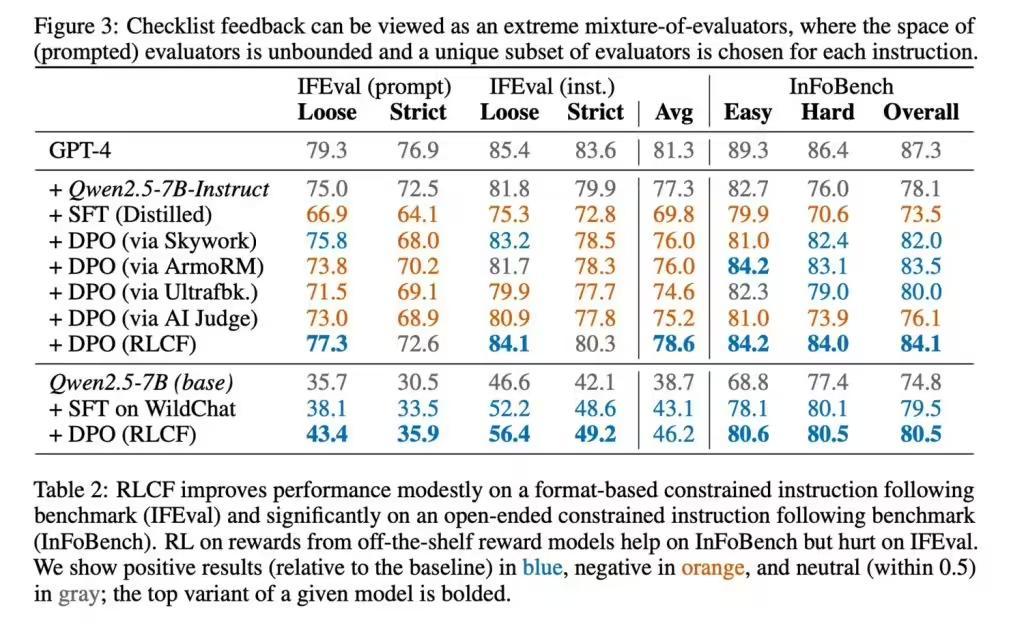
研究团队在名为Qwen2.5-7B-Instruct的强指令跟随模型上测试了这一方法,测试涵盖了五个常用的评测基准。结果显示,RLCF在所有测试中均取得了显著的提升。具体而言,FollowBench的硬性满意率提高了4个百分点,InFoBench提升了6点,Arena-Hard的胜率增加了3点,而在某些任务上,提升幅度甚至达到了8.2%。这些数据充分展示了清单反馈在复杂、多步骤任务执行中的优势。
在清单的生成过程中,苹果的研究团队同样展现出了创新思维。他们利用更大规模的Qwen2.5-72B-Instruct模型,结合现有的研究方法,为13万条指令生成了名为“WildChecklists”的数据集。这些数据集中的清单内容明确且具体,例如“是否翻译成西班牙语?”等二元判断项。随后,大模型会对候选回答进行逐项打分,并将这些分数综合加权,作为小模型训练的奖励信号。
尽管RLCF方法取得了显著的成果,但苹果研究者也坦诚地指出了其存在的局限性。首先,该方法依赖于更强大的模型作为评判者,这在资源受限的场景下可能并不现实。其次,RLCF专注于提升复杂指令的执行能力,并未涉及安全对齐方面的设计。因此,它不能替代安全性评估与调优过程。对于其他类型的任务,RLCF的适用性仍有待进一步验证。