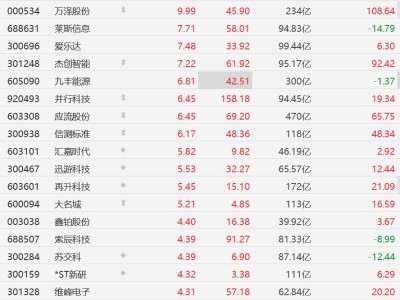
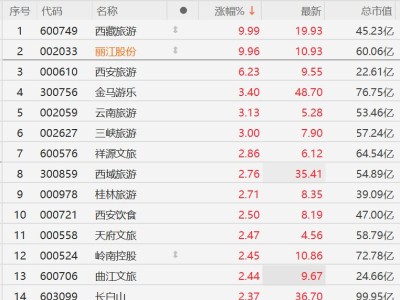
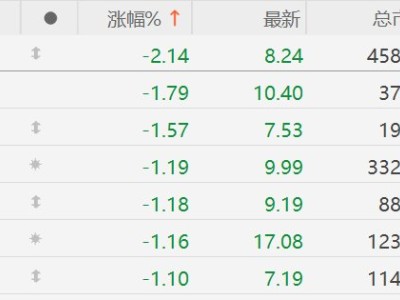
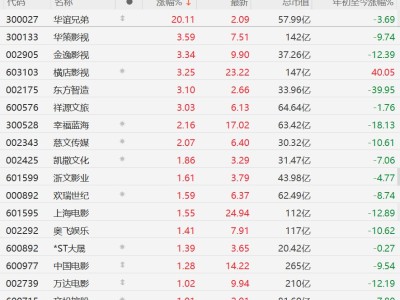
人工智能领域迎来新突破,DeepSeek团队在开源社区Hugging Face正式发布了一款名为DeepSeek-Math-V2的数学推理模型。该模型以2360亿参数的规模亮相,但通过创新的MoE(混合专家)架构设计,实际活跃参数仅210亿,却实现了128K超长上下文处理能力。开源协议采用Apache2.0,彻底解除商业使用限制,发布首日即因全球开发者疯狂下载导致服务器带宽达到峰值。
在数学能力测试中,这款模型展现出惊人实力。零样本思维链(CoT)模式下,MATH基准测试得分达到75.7%,与GPT-4o的76.6%形成直接对标;在美国数学邀请赛(AIME)2024年的30道题目中,成功解答4道,表现优于Gemini1.5Pro和Claude-3-Opus;在Math Odyssey挑战赛中以53.7%的准确率跻身全球顶尖模型行列。这些成绩的取得,得益于其独创的"自验证双引擎"机制——生成器(Generator)负责初步解答,验证器(Verifier)进行逐行校验,通过最多16轮的迭代修正和多数投票机制,配合元验证器有效抑制模型幻觉现象。
训练数据方面,研发团队构建了包含1000亿token的庞大语料库,涵盖学术论文、数学竞赛真题以及合成训练数据。特别引入的GRPO强化学习框架,使模型能够更好地对齐人类偏好。这种数据构建策略带来意外收获:得益于代码与数学混合训练的独特设计,模型在编程任务中同样表现卓越——Humaneval测试集准确率达90.2%,MBPP测试集76.2%,更在SWEBench基准测试中首次实现开源模型突破10%的里程碑,直接比肩GPT-4-Turbo和Claude3Opus等商业闭源模型。
技术实现层面,该模型对硬件资源的需求显著降低。通过优化计算架构,仅需80GB显存的多GPU环境即可完成推理部署。目前完整模型权重已全面开放下载,开发者通过transformers库即可实现一键加载。开源社区正掀起复现热潮,多个技术团队已成功验证模型性能。这款国产开源模型的诞生,标志着在数学推理这个关键领域,开源生态正在突破传统商业巨头的技术壁垒,为全球AI发展注入新的活力。