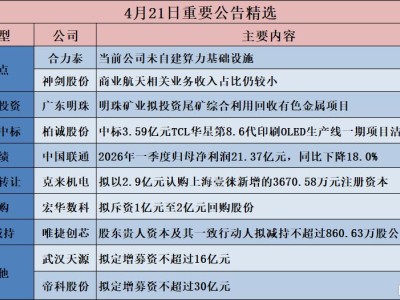
在人类文明演进的长卷中,每一次产业革命都伴随着核心生产要素的更替。从蒸汽机时代对煤炭的依赖,到电气化时代对电力的渴求,再到信息时代对芯片与数据的追逐,这种更迭始终是推动社会变革的根本动力。如今,人工智能技术浪潮席卷全球,一个曾被视为技术术语的概念正悄然崛起,成为驱动数字经济的新引擎——Token,这一原本属于密码学领域的词汇,正在重塑人们对生产力的认知。
四年前提出的"算力即国力"论断,在AI大模型时代迎来了新的诠释维度。当算力、电力、数据与人类智慧(算法)深度耦合,Token成为统合这些要素的核心载体。它已突破区块链技术的边界,从极客圈层的信仰符号转变为全球产业经济的底层逻辑。在人工智能生成内容的链条中,Token既是能源的计量单位,也是信息的存储介质;既是服务的交付凭证,也是货币的价值载体,最终演化为新型生产力的具象化表达。
国家数据局的统计数据显示,2024年初我国日均Token消耗量尚为千亿级别,到2025年6月已暴增至30万亿,增幅达300倍。这个数字背后,是数以百万计的智能芯片昼夜运转,是超大规模数据中心持续扩张,是科研机构与企业的巨额投入。更值得关注的是,这种指数级增长仅是开端,随着多模态大模型的普及,Token消耗量将继续呈现非线性攀升态势。
对于非技术从业者而言,Token可类比为信息世界的"原子"。在大语言模型(LLM)的交互场景中,它是连接人类语言与机器理解的桥梁。当用户输入问题或指令时,分词器会将其拆解为Token序列;模型通过神经网络分析这些单元的组合关系,再生成新的Token序列反馈给用户。这个过程类似于用乐高积木搭建建筑——单个Token可能是单词碎片、像素点或音节,但通过特定规则的组合,却能构建出完整的语义表达。
以英文处理为例,Token既可以是完整单词"Apple",也可能是词根"ing";在中文语境下,它既可能对应单个汉字,也可能涵盖词组单元。这种灵活性使得Token成为跨模态信息处理的通用标准,无论是文本、图像还是音频数据,都能通过抽象化为Token序列实现统一处理。模型的理解深度与回答精度,直接取决于Token的质量与处理效率。
2025年初DeepSeek开源模型的发布,标志着我国AI产业进入高速发展期。各类大模型如雨后春笋般涌现,日均Token调用量突破10万亿大关。这种爆发式增长带来的生产力跃升显而易见,但能源消耗问题也随之凸显。行业开始关注"CO2指标"这一新维度——在保证模型性能的同时,如何提升单位能耗下的有效Token处理量,成为技术优化的核心方向。
在商业应用层面,Token已演变为AI服务的计价单位。用户通过API调用模型时,输入提示词(Prompt)与输出结果的Token数量,直接决定使用成本。这种计量方式促使开发者优化提示词设计,通过精炼表达降低费用。对于需要处理海量数据的企业而言,Token成本优化更是关乎项目可行性的关键因素。例如在长文档处理场景中,如何有效利用上下文窗口限制,成为提升处理效率的重要课题。
多模态模型的发展进一步拓展了Token的应用边界。图像、音频等非文本信息通过特定编码转化为Token序列,使得AI能够处理更复杂的数据类型。这种转变不仅扩大了应用场景,也对Token的序列长度与处理速度提出更高要求。在硬件资源有限的条件下,Token数量直接制约着模型的推理速度与并发处理能力,成为影响用户体验的关键指标。
提示词工程(Prompt Engineering)的兴起,反映了行业对Token利用效率的极致追求。通过优化信息组织方式,开发者能够在有限的Token预算内引导模型生成更高质量的内容。这种技术实践不仅提升了代码生成、数据分析等领域的生产力,也推动着AI从工具向合作伙伴的角色转变。当Token成为连接人类需求与机器能力的纽带,其优化方向便不再局限于技术层面,而是延伸至商业模式、社会伦理等更广阔的维度。