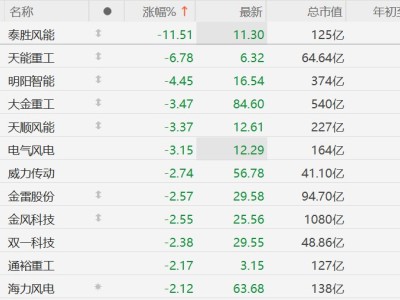
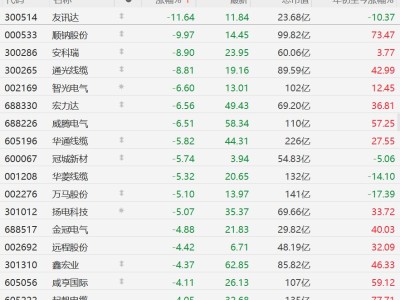
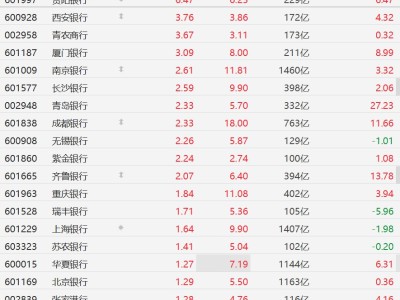
在AI芯片生态日益多元化的背景下,如何降低跨平台软件迁移成本成为行业焦点。近期,众智FlagOS社区推出的KernelGen工具与统一编译器FlagTree组合方案,为算子跨芯片自动生成提供了系统性解决方案。该方案通过自动化工具链覆盖算子开发全生命周期,在华为昇腾、摩尔线程、海光、天数智芯等国产AI芯片及英伟达GPU上完成系统性验证,标志着算子开发模式从手工编码向工程化生产转变。
技术实现层面,KernelGen构建了四层架构体系:用户可通过自然语言、数学公式或现有代码描述需求;大模型驱动的智能体自动生成Triton内核代码;验证层构建多维度测试用例,在目标芯片上与PyTorch参考实现进行数值比对;最后通过性能评估与自动化调优确保执行效率。这种全流程自动化方案将算子开发效率提升数个量级,特别是在多芯片适配场景下,避免了重复开发带来的资源浪费。
统一编译器FlagTree是支撑跨芯片适配的核心基础设施。该项目自2025年启动以来,已支持12家厂商近20款芯片,涵盖DSA、GPGPU、RISC-V AI及ARM等多种架构。通过建立统一的硬件中间表示层,FlagTree将芯片差异封装在编译阶段,使算子生成逻辑无需关注底层硬件细节。最新发布的v0.4版本引入Triton语言扩展机制,提供Lite、Struct、Raw三层编程接口,既保证基础代码的跨平台兼容性,又为性能优化保留灵活空间。
实际评测数据显示,在110个代表性Torch算子的多轮生成测试中,KernelGen取得82%的编译成功率与62%的执行正确率。不同芯片表现呈现差异化特征:华为昇腾在代码生成阶段表现突出,英伟达平台则保持最高的数值准确性。当使用FlagTree编译器时,各平台执行正确率显著提升,特别是在英伟达GPU上达到70%的通过率,较原生编译器提升近20个百分点。这种稳定性优势为后续性能优化奠定了基础。
大模型能力差异在算子生成任务中表现明显。以华为昇腾平台为测试环境,GPT-5展现出最强综合能力,在110个算子中有65个实现完全正确的数值输出。GLM-4.7在复杂算子处理上存在波动,而Qwen3-Max等模型受限于语义理解深度,生成成功率相对较低。这表明算子自动生成不仅需要代码生成能力,更考验模型对数学运算逻辑、边界条件处理等底层机制的理解。
性能优化方面,通过引入模型自反思机制与专家知识库,KernelGen实现显著突破。在英伟达平台测试中,优化后算子执行正确率提升至75.5%,其中68.5%的算子获得超过1倍的加速效果,整体性能中位数达1.04倍。这种持续进化能力证明,算子自动生成已突破"可用"阶段,正在向"高效"方向迈进。特别在融合外部专家知识后,系统能够针对特定硬件特性进行深度调优,这种人机协同模式为AI基础设施发展开辟新路径。
当前行业面临的硬件碎片化挑战,在KernelGen方案中找到破局之道。该工具链通过抽象化硬件差异、自动化生成验证流程,将算子开发周期从数周压缩至小时级。在金融、医疗等对系统稳定性要求极高的领域,这种可验证的数值正确性保障具有特殊价值。随着FlagTree编译器支持的芯片数量持续增长,跨平台算子库的规模效应正在显现,有望解决长期困扰AI落地的"芯片孤岛"问题。