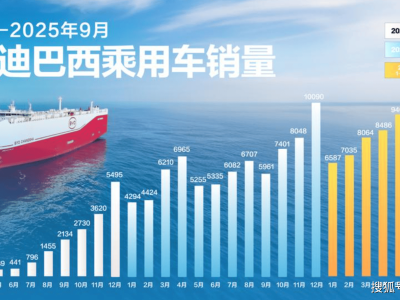
国际计算机视觉大会(ICCV)作为全球计算机视觉领域的顶级学术盛会,即将在风景秀丽的檀香山拉开帷幕。此次大会汇聚了全球顶尖科研力量,苹果公司宣布将携多项突破性成果亮相,成为大会焦点之一。苹果的参与不仅展现了其在人工智能与计算机视觉领域的深厚积累,更通过前沿研究为行业注入新动能。
苹果此次提交的八篇论文覆盖了多模态学习、视频生成等核心领域。其中,“ETVA:通过细粒度问答机制评估文本到视频对齐”的研究提出了全新的评估框架,旨在解决跨模态内容对齐的精准度问题;“MM-Spatial:多模态大语言模型的三维空间理解探索”则聚焦于模型对物理空间的感知能力,为机器人导航、虚拟现实等应用提供理论支持。“STIV:可扩展的文本与图像条件化视频生成方法”和“UniVG:统一图像生成与编辑的通用扩散模型”两项研究,分别从生成效率和模型通用性角度突破,展现了苹果在生成式AI领域的技术深度。
在应用研究层面,苹果机器学习应用研究部经理C. Thomas博士将作为主旨演讲嘉宾,围绕“多模态交互的未来趋势”展开分享。其团队提出的“原生多模态模型扩展规律研究”揭示了模型规模与性能之间的量化关系,为行业提供了可复用的扩展策略。同时,“稳定扩散模型在视觉上下文学习中的隐性优势”研究则通过实验验证了扩散模型在少样本学习场景下的潜力,为小数据条件下的模型训练提供了新思路。
苹果对技术包容性的重视同样体现在大会参与中。公司不仅支持“计算机视觉领域女性研讨会”,还委派资深研究员Patricia Vitoria Carrera和Tanya Glozman担任导师,与全球女性科研者分享经验。这一举措与苹果近期在AI伦理领域的多项倡议一脉相承,凸显了技术发展与社会责任的平衡。
其他论文中,“UINavBench:交互式数字智能体综合评估框架”构建了智能体行为能力的标准化测试体系,为自动驾驶、服务机器人等领域提供了评估工具;“基于多模态提示的统一开放世界分割技术”则通过融合文本、图像等多维度信息,实现了对复杂场景的精准理解。这些研究共同构成了苹果在计算机视觉领域的技术矩阵,覆盖了从基础理论到工程落地的全链条。
随着大会日程临近,苹果的参会阵容和技术成果引发了学术界与产业界的广泛关注。其提交的论文不仅数量领先,更在创新性、实用性上获得同行认可。此次亮相不仅是对苹果技术实力的展示,也为全球计算机视觉社区提供了新的研究方向与合作契机。